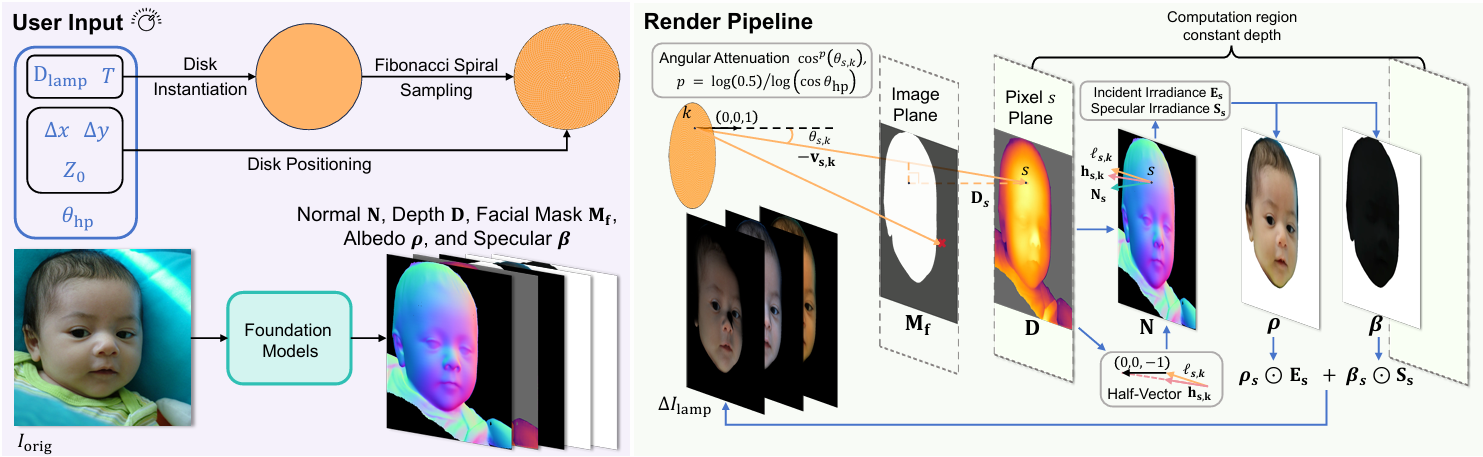
Face fill-light enhancement (FFE) brightens underexposed faces by adding virtual fill light while keeping the original scene illumination and background unchanged. Most face relighting methods aim to reshape overall lighting, which can suppress the input illumination or modify the entire scene, leading to foreground-background inconsistency and mismatching practical FFE needs.
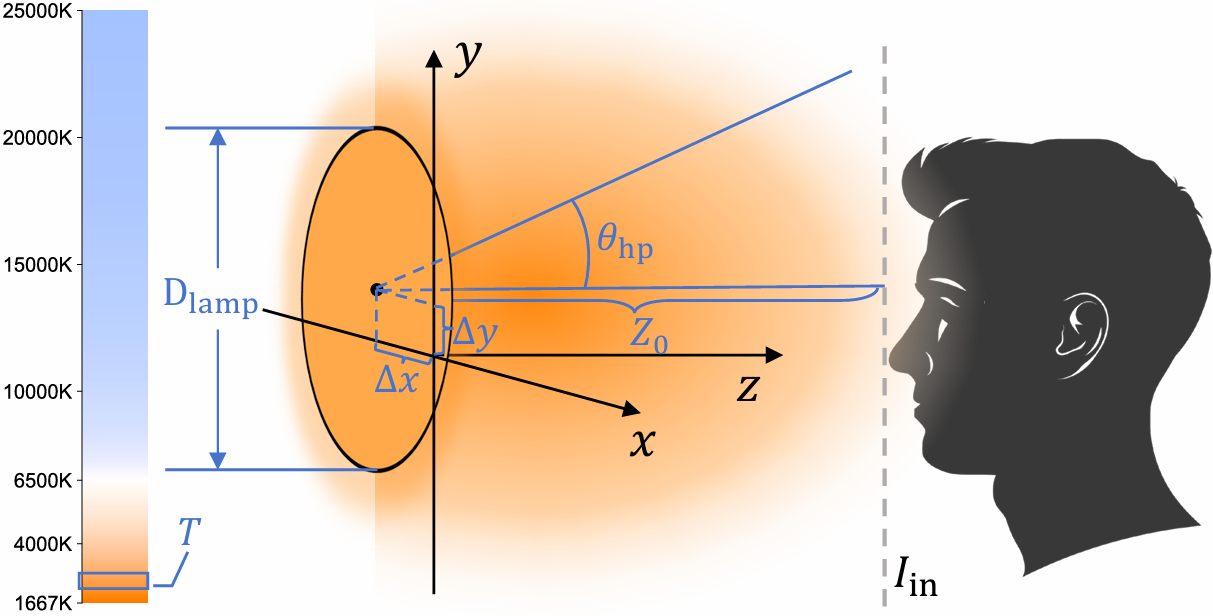
To support scalable learning, we introduce LightYourFace-160K (LYF-160K), a large-scale paired dataset built with a physically consistent renderer that injects a disk-shaped area fill light controlled by six disentangled factors, producing 160K before-and-after pairs.
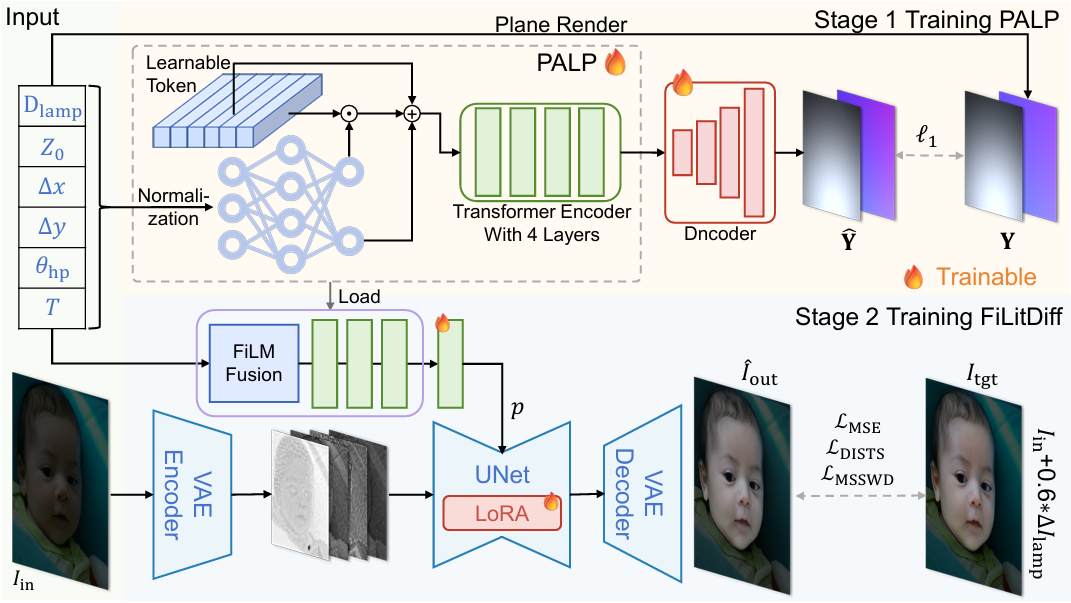
We first pretrain a physics-aware lighting prompt (PALP) that embeds the 6D parameters into conditioning tokens, using an auxiliary planar-light reconstruction objective. Building on a pretrained diffusion backbone, we then train FiLitDiff, an efficient one-step diffusion model conditioned on physically grounded lighting codes, enabling controllable and high-fidelity fill lighting at low computational cost.